
I ran a half-marathon last weekend! It was tough but I think the great thing about running is that you can see so much improvement if you’re prepared to put in some good preparation (using data of course!) combined with a healthy dose of motivation. I felt that the race I entered was dominated by regular runners with very few casual participants (except for me!), so I was interested to investigate: is there a pattern to which races are selected by regulars, and is there a “circuit” that regular marathon-runners prefer?
My training plan looked broadly as follows – it’s very basic but worked for me!

Others have rather impressively put a lot more data analysis into how best to train, as outlined in this lecture I attended recently at Cambridge Science Fair: http://www.pdn.cam.ac.uk/other-pages/schweining/the-physics-and-physiology-of-running
Instead I put my data analysis efforts into analysing the competitor field. There are a surprisingly large number of half marathons – over 250 just in the UK, according to halfmarathonlist.co.uk. I know of many runners that travel far & wide over the world to get to their runs too! Different kinds of runs are becoming more popular these days also, for example mud runs and obstacle challenge courses, triathlons, as well as different distances….but those are less easy to compare between races, so I restricted my data to UK half-marathons.
As for time period, all the results I used were from 2015. Whilst some results were collated on timing-chip websites, others were spread across individual event organisers and running club websites – there was no single source for results, and there was no consistent format either…anyway after a fair bit of data manipulation / cleaning, here are the results!
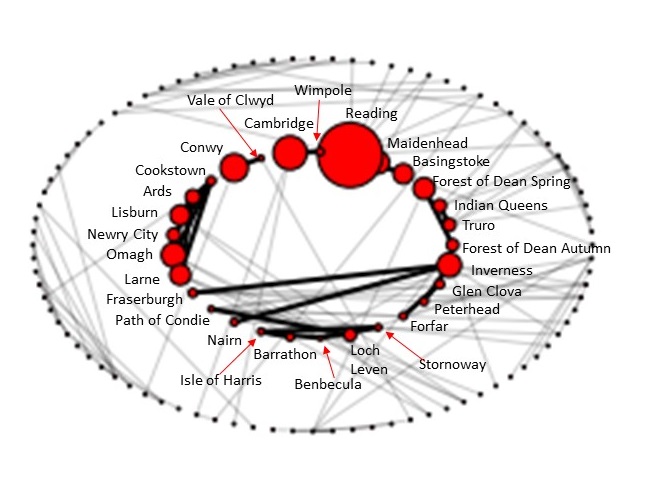
For each pair of half-marathons in the UK set analysed, I calculated how many runners they had in common between them. This was displayed as a proportion of the size of the races, to be able to do a fair comparison between different size races. This was then used to create a network map, where each bubble below represents a race, sized according to its runner population. Each connecting line between two bubbles represents a high % of runners in common between them.

There are several insights to be drawn from this map. Firstly the visible “inner circle” represented the circuit of runs with a high percentage of runners in common with other runs. The largest of these is Reading, positioned in April (so offers a useful warmup for other halfs) in an accessible UK location (so encouraging participation amongst runners in many regions). Reading as you’d expect has many runners in common with Maidenhead, its adjacent bubble, because of its proximity.
It’s interesting to note that some of the huge half-marathons (Cardiff for example) don’t quite make the cut for the “inner circle”. Although its participation is high, this includes a lot of the more casual runners that do a half-marathon as a one-off with friends in fancy dress, say, and then no further runs in the year. The runners that are seeking a personal best, amongst other runs that they do throughout the running calendar, are more put off by the larger runs because of the nature of its high participation.
Another trend in the inner circle, which wasn’t quite as I expected, is a collection of Scottish and Welsh races. This is presumably because there are plenty of runners that regularly run in their own region, and because there less choice of local races and more of a distance to access other regions’ races, they all run the same ones locally.
Are there any others that my running friends recognise as those they would have expected to see on the circuit? Comment below please 🙂
For the more technical amongst you, I created a weighted adjacency matrix from the data and then used Python to plot the map. I only matched runners based on having the same first & last name, so there may be some that match by chance of having the same name but on the other hand some may be missed in the matching because of differing spellings – with more time I would also like to have matched based on similar time results & club names to tighten this up.
This depiction was chosen instead of mapping each runner as a bubble, and connecting them if they ran a race in common, since that rapidly got too blurred a map! Also it would take a lot for a “significant” result to emerge – since even the most keen runners probably couldn’t participate in more than 30 races per year thus reducing the possibility of connections.

Leave a comment